一般而言,SQL 查詢都可以轉換成關聯式運算式,因此關聯式代數運算式的最佳化是 SQL 查詢最佳化的基本課題。而研究關聯式代數的最佳化最好是從研究關聯式代數的等價轉換開始。所謂等價轉換是利用前面章節介紹的轉換方法,如分配律、結合律與交換律,使得轉換前後的兩個關聯式代數運算式有著相同的結果。
通常最佳化查詢的原則是將二元運算,例如:關聯運算、除法運算等,延遲到越後面做越好,儘量讓選擇運算或投影運算過濾掉不需要的值組,以便執行二元運算。
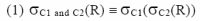
 先利用能過濾較多值組的條件C2 對 R 做篩選(σC2(R)),去掉不合乎條件 C2 的大部份值組,而得到較少資料量的 R1,因此使得再做 σC1(R1) 時,需篩選的資料量變少了,因而會有較好的效能。
先利用能過濾較多值組的條件C2 對 R 做篩選(σC2(R)),去掉不合乎條件 C2 的大部份值組,而得到較少資料量的 R1,因此使得再做 σC1(R1) 時,需篩選的資料量變少了,因而會有較好的效能。
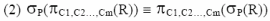
利用上面的等價轉換使得 σP(R) 先做篩選,去掉不合乎條件 P 的值組,如此可以得到較少資料量的中間結果,這樣對後面的查詢操作會有較好的效能。
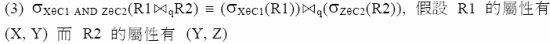
利用上面的等價轉換對 R1 與 R2 先做篩選,去掉不合乎條件的值組,如此可以個別得到較少資料量的中間結果,如此再做關聯會有較好的效能。
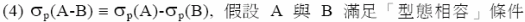
利用上面的等價轉換對 A 與 B 先做篩選,去掉不合乎條件的值組,如此可以個別得到較少資料量的中間結果,如此再做差集會有較好的效能。
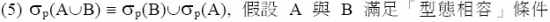
如果能使用 OR 達成查詢的,就儘量不要用 UNION。
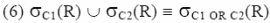
調整資料庫的效能對我們的經驗而言是一種極大的考驗,在這裡並沒有什麼奇妙的方法,只要你對各個應用程式之間的了解比別人還要多,並且要時常勇於嘗試錯誤即可。除了前面介紹利用關聯式代數轉換的方式外,這裡有幾個可以增進效能的方法,可以提供你較快速達成目的:
(1)避免在查詢中使用函數,特別是包含索引列,因為函數的 存在將會關閉索引。
(2)重覆看看在 WHERE 子句中的每一列以決定是否適當
的用了索引,如果一個小型的表格或者 SELECT 指
令接收到大量的資料時,這時使用索引並不是一個明
智的做法,而且你甚至應該停止索引或把它們結束掉
。
(3)設法避免在 LIKE 函數時使用萬用字元 % 符號或是
任一字元 _,如 ENAME LIKE ‘M%’。因為
LIKE 函數會造成完全的表格掃描。儘量用較小且較
明確的範圍做查詢,例如:ENAME BETWEEN
‘Mad’ AND‘Max’。再者別在索引列中使用計
算式,因為這將會關閉掉索引的使用。
(4)不要使用非必須的子查詢。
(5)不要對非必要的欄位發出要求。例如:使用“ * ”符
號以選擇所有的欄位,這通常不是好的做法。
(6)不要對你用不到的列發出要求,所以請謹慎的使用
WHERE 子句做篩選,同樣的,只有在你必須要做群
組總結時,你才可以使用 ORACLE 群組函數中提
供的功能,例如:AVG 或是 MAX。
(7)善用狄摩根定律(DeMorgan’s Law)。
(8)把條件中 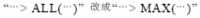 。
。
(9)建議可以選擇利用 ”IN 子查詢” 來代替 “exists
子查詢”。
(10)建議可以將 “IN 條件範圍”轉成多個用 OR 的個別
條件。


