| |
|
 |
|
|
所謂子查詢是指在
WHERE 子句或 HAVING
子句的條件中出現的查詢。相對地,稱包含子查詢的查詢為父查詢或主查詢。因為子查詢使得一系列簡單查詢可以構成複雜的查詢,因此子查詢也稱為嵌套查詢。子查詢的主要作用是用來做為主查詢的條件,子查詢的結果並不被顯示。
|
|
SELECT 敘述的 WHERE 子句中提供比較的值。其用法:
子查詢-SELECT…FROM…WHERE
SELECT…
FROM <表格名>
WHERE <欄位名或欄位運算式> <比較運算子> (SELECT …
FROM <表格名>
WHERE <條件> ) ;
|
 |
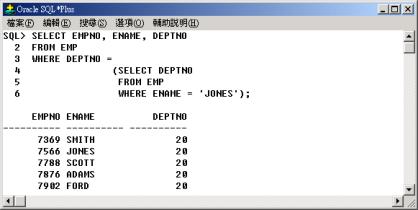
查詢與 JONES
同部門的員工,並列出其員工代碼(EMPNO)、員工名字(ENAME) 與部門代碼(DEPTNO)。
|
| |
|
 |
在上面的例子中,當子查詢傳回
JONES 的部門代碼為 20 時,上面的例子即成為以下的簡易查詢 (即查詢部門 20 員工的資料了):
|
| |
 |
| |
上面的例子除了利用子查詢外,可利用自身關聯的方法:
此外,子查詢可依傳的值與查詢的方式,分為單一記錄值子查詢、多記錄值子查詢、多欄位子查詢與相關子查詢。
|
|
 |
|
|
此類子查詢只傳回單一記錄值,因此所有邏輯運算子
(如 >,=,< 等等) 都可以用。
|
 |
查詢部門的所在地(LOC) 為
DALLAS 的員工,並列其員工姓名(ENAME)、職位(JOB),部門代碼(DEPTNO) 的資料。
|
| |
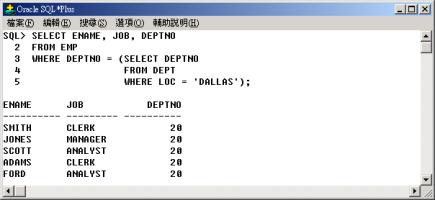
|
|
本例子中,當子查詢傳回部門的所在地為 DALLAS 的部門代碼為 20 時,本例子即成為以下的簡易查詢 (即查詢部門 20
員工的資料了): |
| |
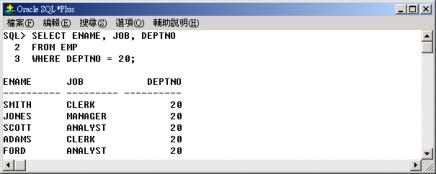 |
|
|
|
|
 |
|
|
此類子查詢傳回不是單一值而是一組資料列。這種查詢必須用多值比較運算子與主查詢相連繫,以下我們將依序介紹多值比較運算子:
|
|
例子中表格
EMP 的外來鍵 Deptno 與表格
Dept 表格中的主鍵 Deptno 關聯。
|
 |
[NOT] IN
表示 [不] 屬於某集合中成員的關係 |
|
[NOT]
ANY:將主查詢中的一個值與子查詢傳回值中的一個值進行比較 |
|
[NOT]
ALL:將主查詢的值與子查詢傳回值中的每個值進行比較 |
|
[NOT]
EXISTS:EXISTS 表示子查詢至少傳回一列時條件成立。而 NOT EXISTS
表示子查詢不傳回任何列時條件成立 |
|
| |
| 1. [NOT] IN 表示 [不]
屬於某集合中成員的關係 |
|
|
| |
|
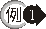 |
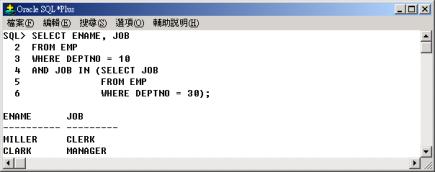
查詢部門 10
中的職位(JOB) 與部門 30 中的相同職位的員工,並列出其員工名字(ENAME) 與職位(JOB)。
|
| |
|
 |
行 4 至行 6
的子查詢傳回部門 30 的所有職位(JOB),做為主查詢的條件,因為部門 30
的所有職位可能不只一種,所以,主查詢的條件的運算子必須用多值比較運算子 IN 與主查詢相連繫。
|
2. [NOT]
ANY:將主查詢中的一個值與子查詢傳回值中的一個值進行比較
|
|
|
 |
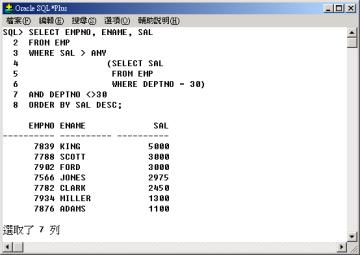
查詢其他部門中的員工,其薪資(SAL) 比部門 30 中其中一個員工薪資高,並依薪資(SAL) 降冪排序列出其員工代碼(EMPNO)、員工名字(ENAME)
與薪資(SAL)。
|
| |
|
 |
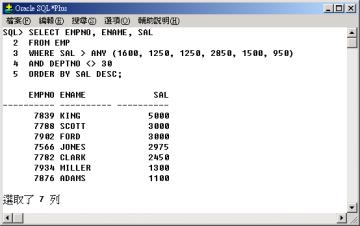
行 4 至行 6
的子查詢回覆部門 30 的所有薪資給主查詢做為篩選條件。由於子查詢的結果 (部門 30 的薪資) 為 1600 , 1250 ,
1250 , 2850 , 1500 , 950,所以例 4 的查詢相當以下的查詢:
|
| |
|
| |
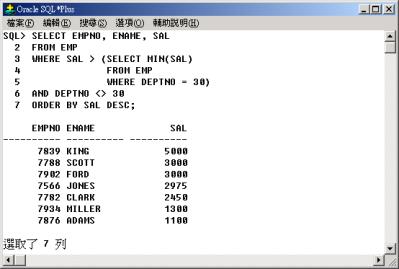
此外我們仔細分析例4
的查詢,其實它相當於查詢其他部門中的員工其薪資(SAL) 比部門 30 中最低薪資(MIN(SAL))
的員工高,並依薪資(SAL) 降冪排序列出其員工代碼(EMPNO)、員工名字(ENAME) 與薪資(SAL)。
例4 的另一種寫法:
|
| |
 |
| |
| 3. [NOT]
ALL:將主查詢的值與子查詢傳回值中的每個值進行比較 |
|
|
| |
|
 |
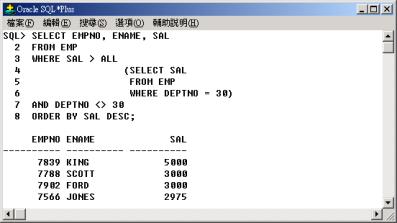
查詢其他部門中的員工,其薪資(SAL) 比部門 30 中所有員工薪資都高,並依薪資(SAL) 降冪排序列出其員工代碼(EMPNO)、員工名字(ENAME)
與薪資(SAL)。
|
| |
|
 |
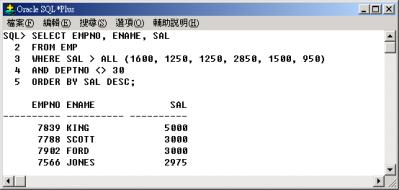
同理例 6
的查詢相當以下的查詢: |
| |
|
| |
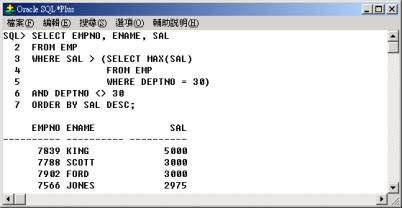
同理,仔細分析上面的查詢,其實它相當於查詢其他部門中之員工的薪資(SAL) 比部門 30 中最高薪資(MAX(SAL))
的員工高,並依薪資(SAL) 降冪排序列出其員工代碼(EMPNO)、員工名字(ENAME) 與薪資(SAL)。
例6 的另一種寫法:
|
| |
|
|
上面改寫的例子在查詢效率上要優於原來的查詢,這是因為改寫形式在執行上更為自然。表 1 列出了 ANY、ALL
與群組函數之間的對應轉換關聯,例如:‘= ANY’相當於‘IN’;‘<> ALL’相當於‘NOT IN’。
|
| |
|
|
ANY
|
ALL
|
|
=
|
IN
|
無對應轉換關聯
|
|
<>
|
無對應轉換關聯
|
NOT
IN
|
|
<
|
<
MAX
|
<
MIN
|
|
<=
|
<=
MAX
|
<=
MIN
|
|
>
|
>
MIN
|
>
MAX
|
|
>=
|
>=
MIN
|
>=
MAX
|
|
| |
表 1:ANY、ALL
與群組函數的同等轉換關聯
|
4. [NOT] EXISTS:EXISTS
表示子查詢至少傳回一列時條件成立。而 NOT EXISTS 表示子查詢不傳回任何列時條件成立。
|
|
|
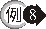 |
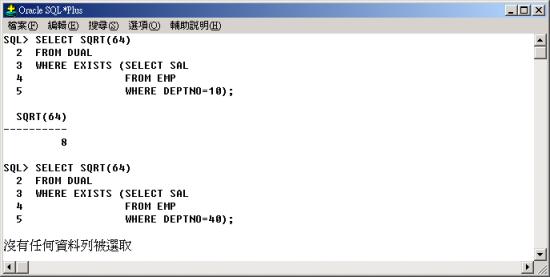
EXISTS 的例子。
|
| |
|
 |
因為部門 10
中有員工,所以查詢員工的薪資資料的子查詢一定會有資料回覆,所以 EXISTS 的條件為 TRUE,因此會把 SQRT(64)
的值 8 回覆。因為部門 40 中沒有員工,所以查詢員工的薪資資料的子查詢沒有資料回覆,所以 EXISTS 的條件為
FALSE,因此不會把 SQRT(64) 的值 8 回覆。 |
| |
|
|
 |
|
|
子查詢中不但可以查出一個欄位的值,還可以查多個欄位。子查詢傳回欄位的個數及型態必須要與主查詢欄位的個數和型態匹配。所以在使用多欄位子查詢時,必須保證與主查詢用括號括起來的多個欄位個數相同、資料型態匹配。
|
 |
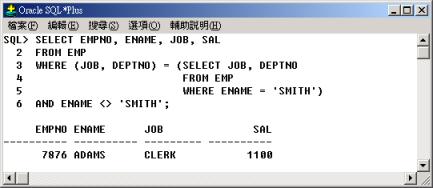
查詢其他員工與 SMITH 有著相同職位(JOB) 和部門(DEPTNO) 的員工,並列出員工代碼(EMPNO)、員工名字(ENAME)、職位(JOB)
和薪資(SAL)。
|
| |
|
|
行 3 至行 5
子查詢中,查詢 SMITH 的職位(JOB) 與部門代碼(DEPTNO) 做為主查詢的查詢的條件。
|
|
 |
|
|
相關子查詢是指子查詢的 WHERE
條件子句中有引用主查詢的查詢列。反之我們稱之不相關子查詢。
|
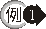 |
查詢沒有員工的部門,並列出部門代碼(DEPTNO) 與部門名稱(DNAME)。
|
| |
|
|
首先從主查詢的表格 DEPT
中取出第一筆記錄並將其 DEPTNO 的欄位值代入子查詢之篩選條件 (EMP.DEPTNO = DEPT.DEPTNO) 的DEPT.DEPTNO
中,然後在行 3 至行 5
的子查詢中,利用篩選條件傳回符合的記錄。若子查詢不傳回任何列時,表示主查詢之篩選條件成立,則列出該記錄的部門代碼與部門名稱,否則不列出。然後再重覆從主查詢的表格
DEPT 中取出記錄並將其 DEPTNO 的欄位值代入子查詢之篩選條件,直到表格 DEPT 的所有記錄都被處理過為此。
|
| |
這種子查詢的 WHERE
條件子句中有引用主查詢的查詢列稱為相關子查詢。
|
 |
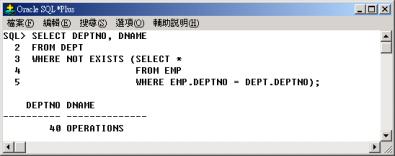
查詢所有員工中,其薪資(SAL) 大於該部門的平均薪資,並列出該名員工代碼(EMPNO)、員工姓名(ENAME)、部門代碼(DEPTNO)
與薪資(SAL)。 |
|
|
| |
|
|
首先從主查詢的表格 EMP A
中取出第一筆記錄並將其 DEPTNO 的欄位值代入子查詢之篩選條件 (DEPTNO = A.DEPTNO) 的A.DEPTNO
中,然後在行 3 至行 5 的子查詢中,利用子查詢傳回EMP A 的第一筆記錄所在部門的平均薪資(AVG(SAL))給主查詢當條件,如果第一筆記錄的薪資(SAL)大於所在部門的平均薪資,則列出第一筆記錄的資料,否則不列出。然後再從主查詢的表格
EMP A 中取出記錄並將其 DEPTNO
的欄位值代入子查詢之篩選條件中,看看該記錄的薪資(SAL)是否大於所在部門的平均薪資,如果成立則列出該記錄的資料,否則不列出。重覆以上的動作直到表格
EMP A 的所有記錄都被處理過為此。
|
 |
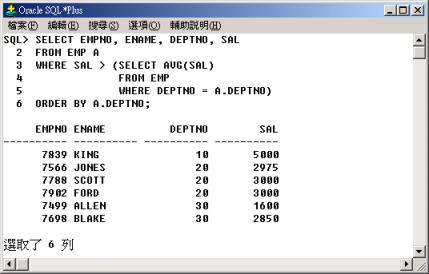
查詢部門中薪資(SAL) 最高三名的員工,並依薪資排序列出其員工名字(ENAME) 與薪資(SAL)。 |
|
|
| |
|
 |
對於薪資(SAL)
最高三名的員工而言,最多只有二名員工其薪資大於他,所以在行 3 至行 5
的子查詢中先找出對於每位員工而言,有多少員工的薪資大於他,然後在主查詢中篩選出最多只有二名員工其薪資大於他的員工。 |
|
|
|
|
 |
|
|
在 UPDATE 敘述中提供更新的值,或是為
WHERE 子句中提供進行比較的值。其用法: |
|
更新-UPDATE 使用子查詢
UPDATE < 表格名 >
SET ( <欄位名1> , <欄位名2> , … ) = (SELECT <欄位名1> , <欄位名2> , …
FROM <表格名>
WHERE <條件> )
WHERE <欄位名或欄位運算式> <比較運算子> (SELECT <欄位名>
FROM <表格名>
WHERE <條件> ) ;
|
 |
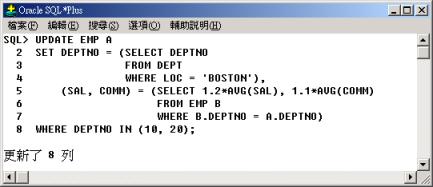
更新所有的部門
10 與 20 中的員工資料,將其部門代碼(Deptno) 更改為部門所在地(LOC)
為‘BOSTON’的部門代碼,再將該員工的薪資(SAL) 更改為原所屬部門平均薪資的 1.2 倍並更改獎金(COMM)
為原所屬部門的平均獎金的 1.1 倍。 |
|
|
| |
|
|
行 2 至行 4
子查詢中,查詢部門所在地(LOC) 為‘BOSTON’的部門代碼做為 DEPTNO 的更新值;行 5 至行 7
子查詢中,利用相關子查詢找出該員工之所在部門的平均薪資與平均獎金並將其乘 1.2 倍與 1.1 倍,做為 SAL 與 COMM
的更新值。
|
|
在
DELETE 敘述的
WHERE 子句中提供進行比較的值。其用法: |
|
|
| |
刪除-DELETE FROM 使用子查詢
DELETE FROM <表格名>
WHERE <欄位名或欄位運算式> <比較運算子> (SELETE <欄位名>
FROM <表格名>
WHERE <條件> ) ;
|
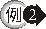 |
刪除獎金(COMM)
佔薪資(SAL) 一半以上的員工資料。 |
| |
|
 |
行 3 至行 4
子查詢中,查詢有那些員工其獎金大於二分之一薪資,並做為刪除記錄的條件。
|
 |
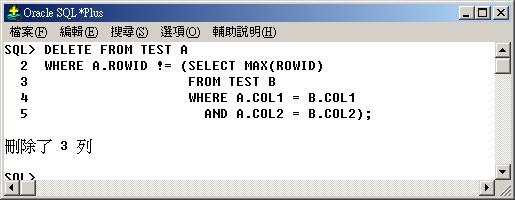
假如表格
TEST 中有兩個欄位(COL1, COL2) 而且記錄中有重覆的值,如何刪除重覆的記錄。 |
|
|
| |
|
|
假設表格 TEST 的包含
ROWID 的資料內容如下:
|
| |
|
ROWID
|
COL1
|
COL2
|
|
AAAFXZAADAAAADTAAA
|
1111
|
1111
|
|
AAAFXZAADAAAADTAAB
|
1112
|
1111
|
|
AAAFXZAADAAAADTAAC
|
1113
|
1111
|
|
AAAFXZAADAAAADTAAD
|
1114
|
1111
|
|
AAAFXZAADAAAADTAAE
|
1115
|
1111
|
|
AAAFXZAADAAAADTAAF
|
1111
|
1111
|
|
AAAFXZAADAAAADTAAG
|
1112
|
1111
|
|
AAAFXZAADAAAADTAAH
|
1111
|
1111
|
|
| |
由上面資料內容中,我們可以觀察到一個重點:每一列不論其值為何,都有一個唯一的 ROWID。若是沒有重覆值的列,其 ROWID
只有一個,反之則 ROWID 就不只一個;也就是說,有重覆值的列,會有兩個以上的 ROWID。所以對於沒有重覆值的 ROWID
而言,在表格中的 ROWID 只有一個,也就說其 ROWID 等於最大的 ROWID (當然也等於最小的 ROWID)。所以我們只要刪除那些
ROWID 不等於 MAX(ROWID) 的列,即可刪除重覆的列了。因此,我們利用相關子查詢來做。所以在行 2 至行 5
的子查詢中,找出每一個相同值的列中最大的 ROWID,若是該列的 ROWID 不等於相同值之最大的 ROWID,則刪除該列。
|
|
在
INSERT 敘述中提供插入的資料列,其用法: |
|
|
| |
插入-INSERT INTO…
INSERT INTO <表格名> ( <欄位名> , <欄位名> , … )
SELECT (<欄位名> , <欄位名> , … )
FROM <表格名>
WHERE <欄位名或欄位運算式> <比較運算子> (SELECT <欄位名>
FROM <表格名>
WHERE <條件> );
|
 |
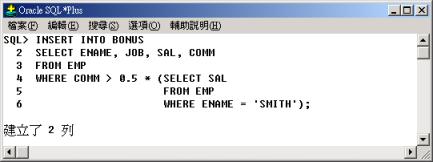
將公司中符合獎金(COMM)
大於二分之一員工 'SMITH' 的薪資 (SAL) 條件之員工資料加入 BONUS 表格中。
|
| |
|
|
行 4 至行 6
子查詢中,查詢 SMITH 的薪資並乘上 0.5 做為行 2 至行 4 的篩選條件,再將查詢的結果插入 BONUS 表格中。
|
|
在
CREATE TABLE 命令中提供插入的資料列,其用法: |
|
|
| |
建立-CREATE TABLE AS….使用子查詢
CREATE TABLE <新表格名> AS
SELECT <欄位名> , <欄位名> , …
FROM <表格名>
WHERE <欄位名或欄位運算式> <比較運算子> ( SELECT <欄位名>
FROM <表格名>
WHERE <條件> );
|
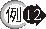 |
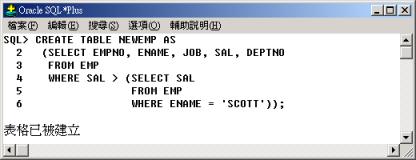
將 EMP
表格中符合薪資(SAL) 大於員工 SCOTT 的薪資條件之員工資料複製到 NEWEMP 表格中。 |
| |
|
 |
行 4 至行 6
子查詢中,查詢 SCOTT 的薪資做為行 2 至行 4 的篩選條件,再將查詢的結果產生一個新的表格 NEWEMP。 |
|
| |


